오랜만에 글을 쓰게 되었습니다. 최근에 엘리스 3차 프로젝트를 하느라 글을 못 쓰고 있던 상황이었는데, 얼마 전에 엘리스 3차 프로젝트가 끝남과 동시에 수료를 하게 되었습니다.
따라서 이번에는 엘리스 3차 프로젝트 후기 및 수료에 대한 소감에 대해서 글을 써보려고합니다.
1. 3차 프로젝트의 팀 구성
엘리스 AI 트랙의 3차 프로젝트는 4월 15일 부터 5월 20일 까지 진행되었습니다. 팀은 4월 15일 정도에 발표가 되었는데, 정말 다행스럽게도(?) 제가 평소에 이 분이랑 같이 팀으로 활동하면 정말 좋겠다... 싶은 분들이 많이 계셔서 이번엔 진짜 엄청난게 나오겠는데? 라는 생각을 무의식적으로 하게되었습니다.
저희 팀은 6인 팀으로, 프론트엔드 3명, 백엔드 3명 이렇게 구성이 되었습니다. 프론트엔드에서 한 분이 전체 팀장을 맡아주시기로 하였고, 백엔드의 경우에는 제가 백엔드 개발리드를 맡아서 진행하기로 하였습니다. 그렇게 3차 프로젝트를 향한 여정이 시작되었습니다.
2. 프로젝트 기획
각자의 포지션이 나뉘고나서 프로젝트의 주제를 결정하기로 하였습니다. 저희 팀은 자연어 처리 프로젝트를 진행해야했기 때문에, 사실 주제를 결정하는게 매우 힘들었습니다. 왜냐면 저희가 정해야할 주제는 크게 아래의 2가지 조건을 만족해야했기 때문입니다.
- 진행하려고 하는 주제가 데이터셋이 풍부한가? 그리고 신뢰할만한 데이터셋을 얻어낼 수 있는가?
- 목적함수가 명확하게 떨어질 수 있는 주제인가? (AI Model의 목적이 뚜렷한가?)
코치님의 조언과 팀원 간의 논의 끝에 저희 2팀 (효상이네)는 일기를 작성하면 야식을 추천해주는 커뮤니티 프로젝트 를 하기로 하였습니다. 나름 타당한 주제였던 이유가, 일기를 입력하면 일기에 담긴 감정을 분석하고, 분석된 감정을 토대로 야식을 추천해주는 시스템을 구축한다고 한다면 문장 단위의 감정 분석(sementic analysis)에 대한 데이터셋은 이미 매우 풍부하게 존재했으며, 또한 사전학습된 모델또한 존재했기 때문입니다.
저희의 프로젝트 이름은 EEUM 으로 결정되었습니다. 프로젝트 이름이 결정된 이후에는 EEUM을 만들어가는데 있어서 필요한 기능들이 무엇이 있는지에 대해서 팀원들과 논의를 주고받았고, 어느 정도 기능이 정해진 다음에 크게 어떠한 기술을 사용해서 프로젝트를 구성할까? 에 대해서 논의를 진행하였습니다.
3. 프로젝트 기획까지는 호기롭게 진행되었지만...타스는 다들 처음인걸 😭
기술스택을 논의하는 과정에서 팀원 6명 전원이 타입스크립트 를 사용하자는 의견이 합의가 되었습니다.
하지만 문제가 될것이 있었다면, 저를 제외한 팀원 5명이 타입스크립트를 한번도 사용한 적이 없었으며, 타입스크립트 외에도 객체지향 언어를 한번도 사용한 적이 없는 사람들이었다 는 점이었습니다.
이를 어떻게 극복해나가야할까에 대해서 팀원들과 논의하고, 코치님의 의견을 종합해본 결과, 타입스크립트 경험이 있는 제가 나머지 5명의 팀원들을 대상으로 타입스크립트를 강의하기로 결정하였습니다.
그래서 프로젝트 5주 중 첫주는 팀원들 대상으로 타입스크립트를 강의하고, 백엔드를 대상으로는 객체지향 과 Nest.js 에 대해서 강의하는데 시간을 할애하였습니다.

그리고 동시에 첫 주 동안 프로젝트를 진행하기 위한 그라운드를 만들어두기로 하였습니다. 아무 코딩도 하지 않는 첫 주 동안에 제가 진행했던 사항은 아래와 같습니다.
- 프론트엔드와 백엔드 모두 Docker image를 정의한다.
- 운영 환경을 셋팅한다. VM에 필요한 것을 모두 셋팅하거나, 혹은 빌드서버를 구성하는 등의 시스템을 구성하였다.
- Jenkins를 셋팅하고 Jenkins 빌드 파이프라인을 프론트엔드, 그리고 백엔드에 모두 셋팅하였다.
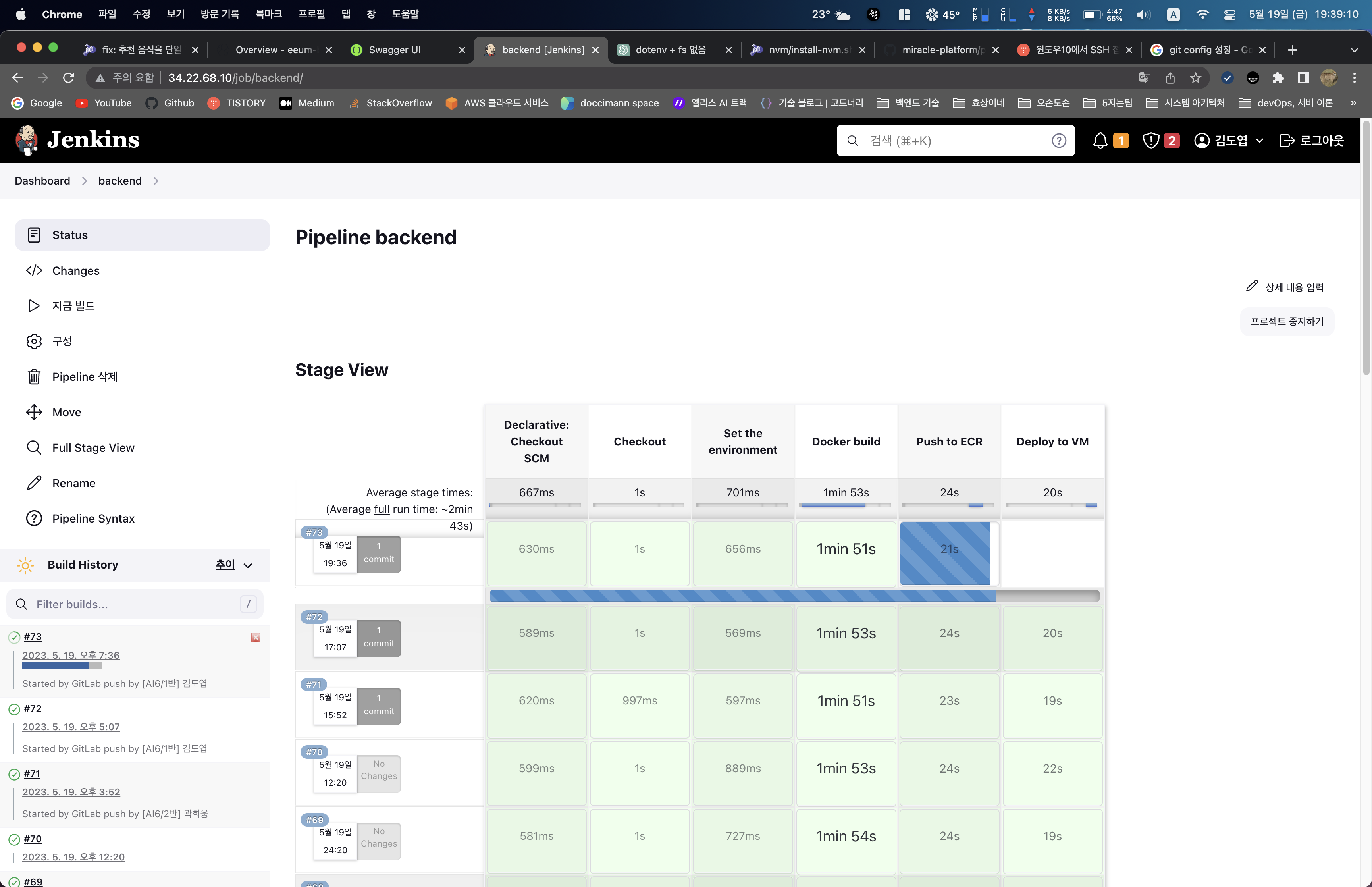
4. 본격적인 코딩 시작
저희 팀은 둘째주가 되어서야 본격적으로 코딩을 시작하였습니다. 사실 본격적으로 코딩을 시작하기 이전에 해야할 일이 하나 있었습니다. 바로 프로젝트 기간 산정 이었습니다.
정확한 기간 산정을 하기 위해서 첫번째로 해야했던 일은, 프로젝트 전반의 기능 구현에서 유스케이스를 모두 뽑아내고, 유스케이스 내부에서 feature를 모두 뽑아낸 다음 feature 단위로 기간 산정을 수행한다 였습니다.
그리고 feature에 들어가는 공수들을 모두 종합한 다음, 남은 기간을 대략 3주 정도로 한정지은 다음 구현이 안될 것 같은 기능은 과감히 소거하는게 두 번째 할 일 이었습니다.
그리고 소거된 이후에 남은 유스케이스들을 주 단위 sprint 단위로 나눈 다음 Jira 티켓을 팀원들에게 발행하였습니다.

그 이후부터는 팀원들이 티켓을 처리할 때 마다 팀원 간의 코드 리뷰 이후에 Develop 브랜치에 머지하도록 함으로써 팀원들이 코드에 대한 이해도를 높여가면서, 그리고 Develop 브랜치에 안정된 코드가 머지되어 배포가 되도록 함으로써 전반적으로 프로젝트의 안정성을 높여갔습니다.
5. 그런데 다 좋다 이거야...그런데 AI는 어떡하지?
사실 프론트엔드, 백엔드는 관성적으로 CRUD를 만들어가면 어느 정도는 되는 일이지만 (물론 중간에 기술적 챌린지가 없다는 것도 아니지만...), AI는 모든 팀원이 겨우 3주 밖에 배우지 않은 상황이었기 때문에 가장 큰 골칫거리였습니다.
이에 대해서 팀원들끼리 논의해본 결과, 아래와 같이 합의가 이루어졌습니다.
- 프론트엔드가 데이터 수집 및 전처리를 전반적으로 담당한다.
- 백엔드가 AI 모델링을 책임진다.
백엔드가 AI 모델링을 책임지게 된 상태에서, 백엔드 개발리드인 제가 생각하기에 제가 AI 모델링에서 큰 책임을 가지고 해야한다고 생각했습니다. 이유는 아래와 같았습니다.
다른 팀원들은 아직 Nest.js 자체에 대해서도, 그리고 타입스크립트에 대한 이해도도 떨어지는 상황인데, AI 모델링까지 시켰다간 전반적인 프로젝트 생산성이 저하될 것 같다
그렇다고 해서 백엔드 개발리드인 제가 지나치게 많은 책임을 지는 것도 그렇게 좋지 못한 상황이라고 백엔드 코치님께서 말씀해주셔서, 제가 가지고 있던 책임 일부를 백엔드 다른 팀원들에게 분배함으로써 조금은 편하게(?) AI를 모델링 할 환경이 마련되었습니다.
CNN, RNN 까지만 익힌 제가 장문의 감정분석을 꽤 높은 스코어가 나오게 모델링하는건 좀 힘들겠다고 판단되어, 가능한 공부는 최대한 하고 모델링을 해보기로 하였습니다. 따라서 제가 AI를 모델링 하기 위해 했던 것들은 아래와 같습니다.
- Attention is all you need 라는 논문을 2회독 한다. 그리고 필요한 사전지식 (Gradient Highway model, Attention 기법, Batch Normalization 기법 등...)을 충분히 학습한다.
- Pytorch에 대해서 학습한다. 사실 지금까지 배운건 Tensorflow인데, 막상 내가 사용할 모든 모델은 Pytorch 기준으로 되어있더라...
- Huggingface에 있는 Transformer API를 이용하여 모델 하나를 예시로 만들어보자.
6. 어떻게 모델링을 하기는 했는데...배포는 어떡하죠?
모델링을 끝내고, 정확도 대략 70%의 감정 분석 AI 모델을 완성했습니다. 하지만 제 앞에는 배포라는 아주 큰 산이 기다리고 있었습니다.
처음에는 Docker로 배포하면 뚝딱 아니야? 라고 간단하게 생각해봤으나, 결국 AI 모델을 서버에 inference 시켜서 배포해야만 AI 모델을 사용할 수 있었기에 정말 어떻게 해야하지? 라는 생각만 가득했었습니다.
배포 방법에 대해서 코치님께 물어보았지만, 인공지능 코치님은 AI 모델링만 하시는 분이지, MLOps를 하시거나 혹은 백엔드를 해보신 분이 아니기에 음...저희 회사는 Kubeflow를 사용하긴해요 라는 답변만을 하셨습니다.
하지만 Kubeflow는 첫째로 Kubernetes 기반으로 프로젝트를 운영해야만 사용 가능한 방법인데다, 둘째로 Kubernetes를 사용한다고 하더라도 Airflow를 사용해야한다는 뜻이기에 Kubeflow를 사용할 수는 없었습니다.
따라서 ai 서버를 배포하는 것은 저희 팀 스스로 해결해야만 했습니다. 결국 선택한 방법은 flask 기반의 서버를 만들고 그 서버를 Docker로 배포하자 였습니다.
백엔드 팀원 전체가 Python 기반의 서버를 만들어본 적도, 그리고 저조차 파이썬 기반의 서버를 만들어본적이 없었기 때문에 정말 막막했습니다. 그래도 Spring과 Nest.js를 해본 제 입장에선 파이썬이라고 뭐 다르겠냐. 구조는 똑같겠지 라는 생각으로 어떻게든 flask 백엔드를 구성했습니다.
GitHub - doccimann-personal-projects/EEUM-AI: 엘리스 AI트랙 6기 3차 프로젝트 EEUM의 AI 서버 레포지토리 입니
엘리스 AI트랙 6기 3차 프로젝트 EEUM의 AI 서버 레포지토리 입니다! Contribute to doccimann-personal-projects/EEUM-AI development by creating an account on GitHub.
github.com
그리고 배포하려고 Docker build를 수행했는데, Docker image의 크기가 10gb나 되었던 것을 발견하였습니다. 게다가 빌드 서버의 HDD 용량은 30GB밖에 안되었기 때문에, 2번의 배포 이후에 빌드 서버 자체가 뻗어버렸습니다.
No space left on this device
따라서 어떻게든 Docker 이미지의 용량을 줄여야하는 기술적 챌린지가 발생해버렸는데, 해결 방법은 아래와 같았습니다.
- pip install 과정에서 남는 빌드 캐시를 모조리 제거한다. 이러한 빌드 캐시가 이미지에도 포함되는 현상을 관측하였기 때문이다.
- Docker build가 끝나고 VM에 배포가 끝나면 system prune 명령어를 통해서 남아있는 도커 빌드 캐시를 제거한다. 이를 통해 HDD 용량을 확보한다.
하지만 기술적 챌린지가 여기서 끝나지는 않았습니다.
7. AI 서버 배포는 끝났는데...그래서 일기 작성 이후에 분석은 어떻게 시키지?
저희는 Nest.js 서버를 메인으로 하여 대부분의 엔드포인트를 여기에 두고, AI 서버는 장문에 대해서 감정 분석을 하는 역할만 쥐어줄 생각이었습니다.
그러면 결국 Nest.js 서버를 통해 사용자가 일기를 등록을 하고, 등록된 일기를 어떻게든 AI 서버가 캐치해서 감정 분석을 하고 음식을 추천해서 Database에 등록을 해야하는 상황인데, 이를 어떻게 또 해결할지가 큰 문제였습니다.
팀원들과의 논의 끝에 아래의 4가지 방법을 생각해봤습니다.
- Cron Job을 하나 정의해서 AI 서버가 감정 분석이 수행되지 않은 일기들 을 분석하도록 작업을 정의해준다. 물론 감정분석이 수행되었는지 여부를 알려주는 컬럼을 하나 추가하고 인덱스를 적용한다면 테이블을 풀스캔하지 않아도 될 수 있다.
- Redis를 도입하고 Redisson 라이브러리 등을 통해 Pub/Sub 구조의 서버간 통신을 구현한다.
- Amazon SQS를 이용해서 메세지 큐 기반의 Pub/Sub 구조의 서버간 통신을 구현한다.
- Axios 통신을 이용해서 서버간 통신을 처리한다.
결국엔 세번째 방법을 통해서 문제를 해결하기로 하였습니다.
첫번째 방법의 경우 제일 간단한 방법이지만, 문제는 트래픽이 조금이라도 몰리면 AI 서버의 일기 처리 속도가 늦어져서 성능이 들쭉날쭉 할 수도 있다는 우려가 존재한다는 점이 존재했습니다.
두번째 방법의 경우 일기 작성과 감정 분석 하나를 처리하자고 학습곡선을 가져가는건 매우 비효율적이라 판단하여 배제했습니다.
네번쨰 방법의 경우도 어쩌면 간단한 방법일수도 있겠지만, 아래의 우려사항들이 존재했습니다.
- 우선 기본적으로 일기 감정 분석이 아무리 일기가 짧더라도 레이턴시가 500~800ms 사이로 측정이 되었다.
- 그런데 매우 장문이면 레이턴시가 2s를 충분히 넘을 수가 있다고 팀원들이 판단하였다.
게다가 사용자 입장에서는 일기 작성 완료 버튼을 눌렀는데 완료에서 넘어가지 않으니 따닥이를 해버릴 우려가 존재하기 때문에 일기 작성 자체의 레이턴시를 줄여야한다 라는 챌린지도 존재했습니다.
따라서 SQS 기반의 pub/sub 구조를 가져감으로써 일기 작성 자체만 처리하고 메시지를 발행함으로써 일기 분석에 대한 레이턴시를 일기 작성에 반영하지 않을 수 있게되었고, SQS는 AWS의 매니지드 메시지큐 서비스이기 때문에 특별한 관리포인트가 추가적으로 발생하지는 않았습니다.
8. Elastic APM 적용 및 프로젝트 마무리. 그리고 발표
5주차가 되고 화요일 즈음에 거의 모든 기능을 구현하였습니다. 그리고 본격적으로 서버 성능을 측정하기 위해서 APM을 붙일 필요가 있었습니다.
따라서 저는 많은 APM 서비스 중에서 Elastic APM을 선정하여 프로젝트에 적용하였고, 그를 통해 서버의 실시간 tpm (transaction per minute)를 측정할 수 있었으며, 동시에 실시간 Latency를 측정할 수 있었습니다.
저희가 만든 서비스는 거의 모든 로직이 평균적으로 40ms 정도의 레이턴시를 보였으며, 로그인 로직의 경우 평균적으로 120~130ms 의 레이턴시를 보이는 것으로 관측되었습니다.
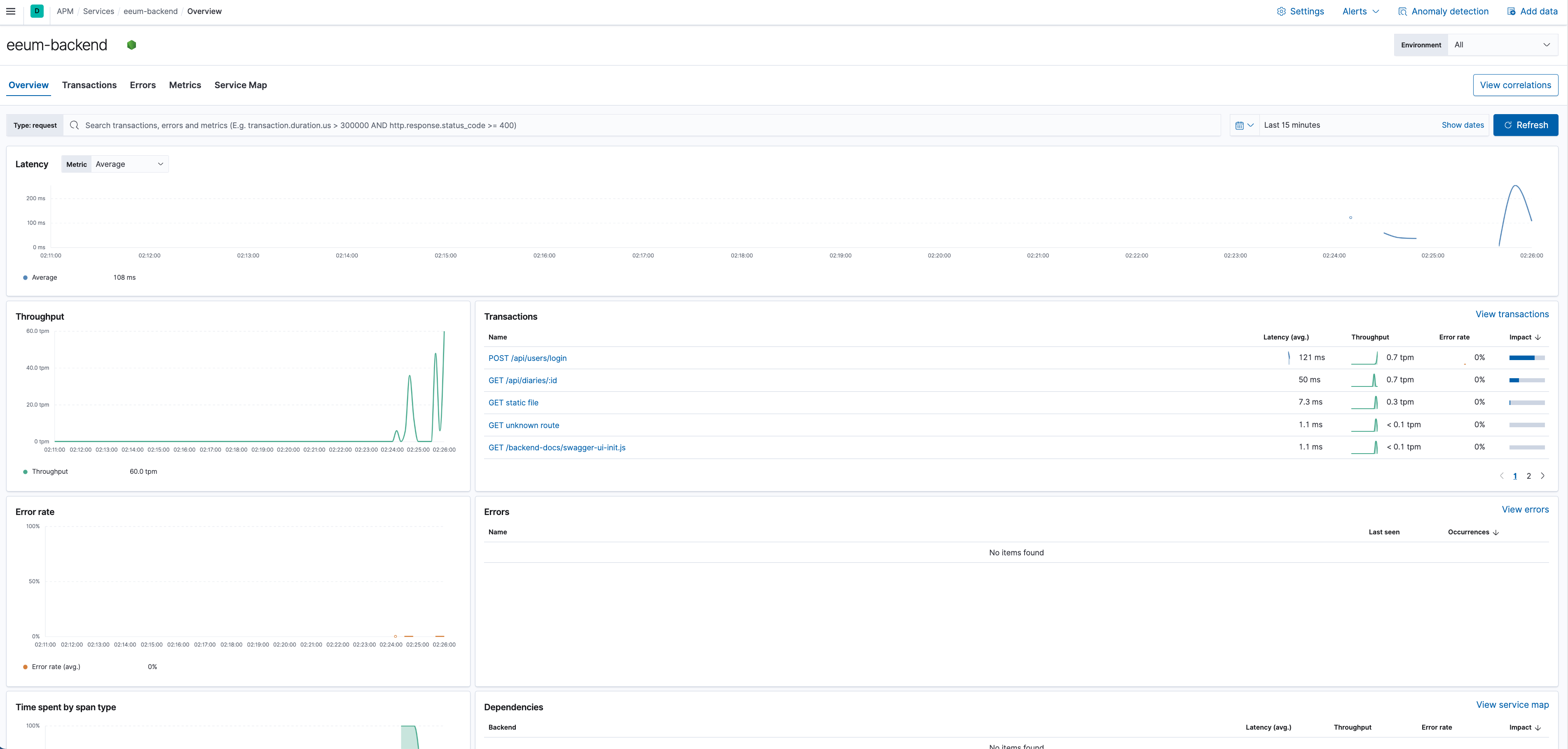
저희 팀은 다행스럽게도 누군가가 데브옵스 전반을 책임지고 있었기에 막판에 배포로 인해서 고통을 받지 않았기에 마지막 5주차는 매우 여유로운 상태로 프로젝트를 마무리 지을 수 있었습니다. (물론 그게 접니다)
그리고 토요일에 발표 및 수료식을 하고 6개월의 길다면 긴 엘리스 AI트랙 6기 여정을 끝마쳤습니다.
9. 3차 프로젝트, 그리고 엘리스 AI 트랙을 마무리 한 소감
우선 3차 프로젝트 소감을 말씀드려보겠습니다. 엘리스 AI트랙에서 진행한 1, 2, 3차 모든 프로젝트 중에서 제일 행복했던 프로젝트가 아니었을까 싶습니다. 엄청 매우 열정적인 팀원, 그리고 긍정적인 분위기, 궂은 일도 마다하지 않았던 저희 팀원들이 있었기에 엄청 성공할 수 있었던 프로젝트가 아닌가 생각합니다.
그리고 3차 프로젝트에 함께 해주셨던 백엔드 코치님을 통해서 매우 많은것을 깨달았습니다. 개발은 흔히 팀원들과 함께 시간을 달리는 프로그래밍 여정 이라고들 많이 비유를 하십니다. 그렇기에 사실 프로그래밍 실력이 개발의 전부가 아니며, 그 외에 소프트 스킬 (긍정적인 스크럼을 만들어내는 방법, 프론트엔드와의 갈등은 어떻게 해결해야할까?, 프로젝트 계획은 어떻게 잡아야만 실패하지 않는 프로젝트가 되는가? 필요없는건 소거해낼 용기가 필요하다)들이 있어야만 성공적인 개발팀을 만들어낼 수 있음을 저에게 많이 알려주었으며, 그를 통해 엄청 많은 성장을 할 수 있었지 않았을까? 라고 돌이켜 생각해봅니다.
6개월 간의 엘리스 AI 트랙에 대한 후기를 남겨보겠습니다.
엘리스 AI 트랙에 들어오기 전까지의 저를 비유하자면 메뚜기마냥 신기술에만 젖어있는 Spring 개발자 라는 문장으로 축약이 가능하지 않을까 생각합니다.
엘리스 AI 트랙을 달리면서 JavaScript, Node.js, TypeScript 등의 기술을 배웠지만, 사실 제가 6개월을 돌이켜보면 그러한 기술스택보다는 소프트 스킬들을 엄청 많이 얻어갔으며, 동시에 기술적 욕심을 내려놓는 연습을 매우 크게 하지않았을까 싶습니다.
백엔드 세상에는 MSA를 하지 않으면 너는 실패한거야 라는 분위기가 어느 정도 형성이 되어있습니다. 그리고 저또한 그러한 분위기에 휩쓸려서 개발로써 비지니스 문제를 해결하기 보다는 매우 화려하게, 복잡하게 비지니스 문제를 해결해야만 문제를 잘 해결한 것이다 라는 마인드에 젖어있었습니다.
하지만 엘리스 AI 트랙을 달리다보니 제가 매우 틀렸던 생각을 하고 있었음을 깨닫게 되었습니다. 물론 신기술을 아는건 중요하긴 하겠으나, 사실 그 정도의 신기술이 없더라도 문제는 충분히 해결할 수 있으며, 오히려 문제의 본질에 집중하는게 개발자의 역량 중 하나이다. 라고 2차 프로젝트의 백엔드 코치님께서 말씀을 하셨던 바 있었습니다.
그 외에도 좋은 동료, 그리고 좋은 코치님, 그리고 문제가 발생할 때 마다 적극적으로 저와 이야기를 해주신 엘리스의 매니저님들이 계셨기에 정말 안정적으로 잘 수료할 수 있었지 않았을까? 라고도 생각합니다.
6개월 동안 저를 스쳐갔건, 혹은 저와 함께 무엇을 같이 해보았건, 그러한 모든 분들께 매우 감사하다는 말씀을 드리면서 글을 마치겠습니다.
'주저리주저리' 카테고리의 다른 글
| Elice AI트랙 1차 프로젝트 (밈팔이닷컴) 회고 (0) | 2023.02.14 |
|---|---|
| Elice AI 트랙 1차 스터디 (백설기 팀) 회고 (2) | 2023.01.19 |